Neural Networks and Deep Learning
Introduction
Neural Network
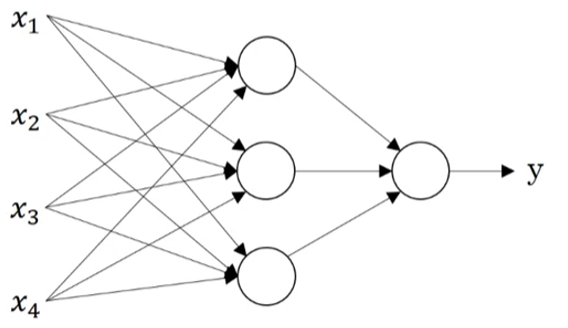
- Use the given input x to predict output y. Inputs are called input layer.
- the circles are called hidden units, use input features to output another features. The units in a column are called a hidden layer.
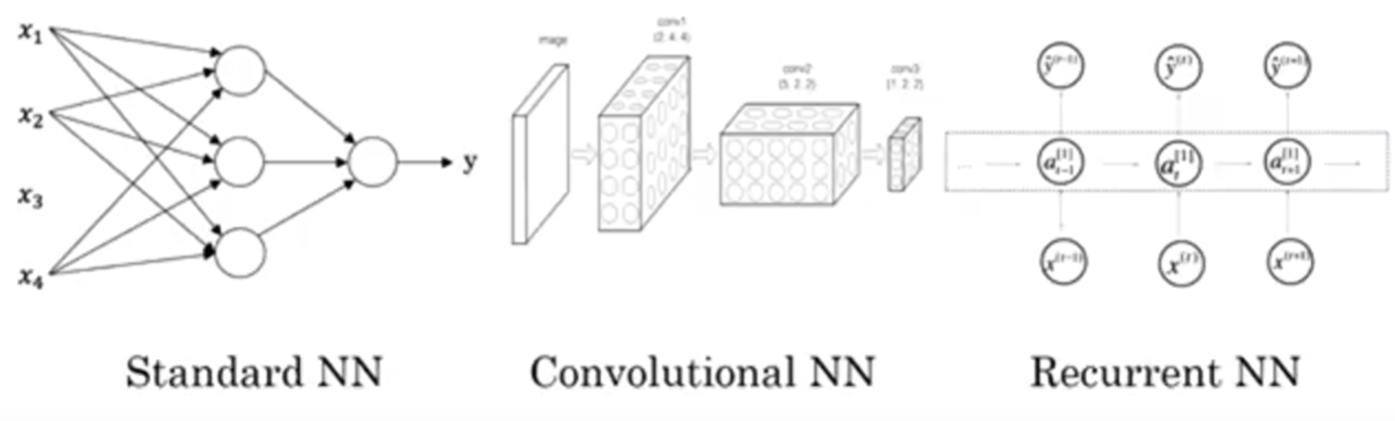
Supervised Learning
- Structured Data: Basically databases of data. Each of the features has a defined meaning.
- Unstructured Data: Data like audio, image and text.
Drivers behind deep learning
- Scale: Large NN performs much better with a large amount of labeled data.
- Algorithms: From sigmoid to ReLU to solve gradient descend.
- Computation
Neural Network Basics
Binary Classification
Learn a classifier that can input a feature vector x and predict the corresponding label y is 1 or 0.
Notation
-
\((x,y)\): A single training example where \(x\) is a \(n_{x}\) dimension feature vector and \(y\), the label, is either 0 or 1.
-
\(m\): Number of training examples. Training examples are denoted from \((x^{(1)},y^{(1)})\) to \((x^{(m)},y^{(m)})\)
-
matrix \(X\) represents training examples in a compact way.
The width and height of the matrix are \(m\) and \(n_{x}\) respectively.
- Label \(y\) can also be denoted by stacking \(y\) in columns.
Logistic Regression
Given an input feature vector \(x \in R^{n_{x}}\), we want to get \(\hat{y}=P(y=1|x)\) as the probability of the chance that \(y\) is equal to 1.
When implementing logistic regression, our job is to learn the parameters \(w \in R^{n_{x}}\) and \(b \in R\), so that \(\hat{y}\) can be got by the following way:
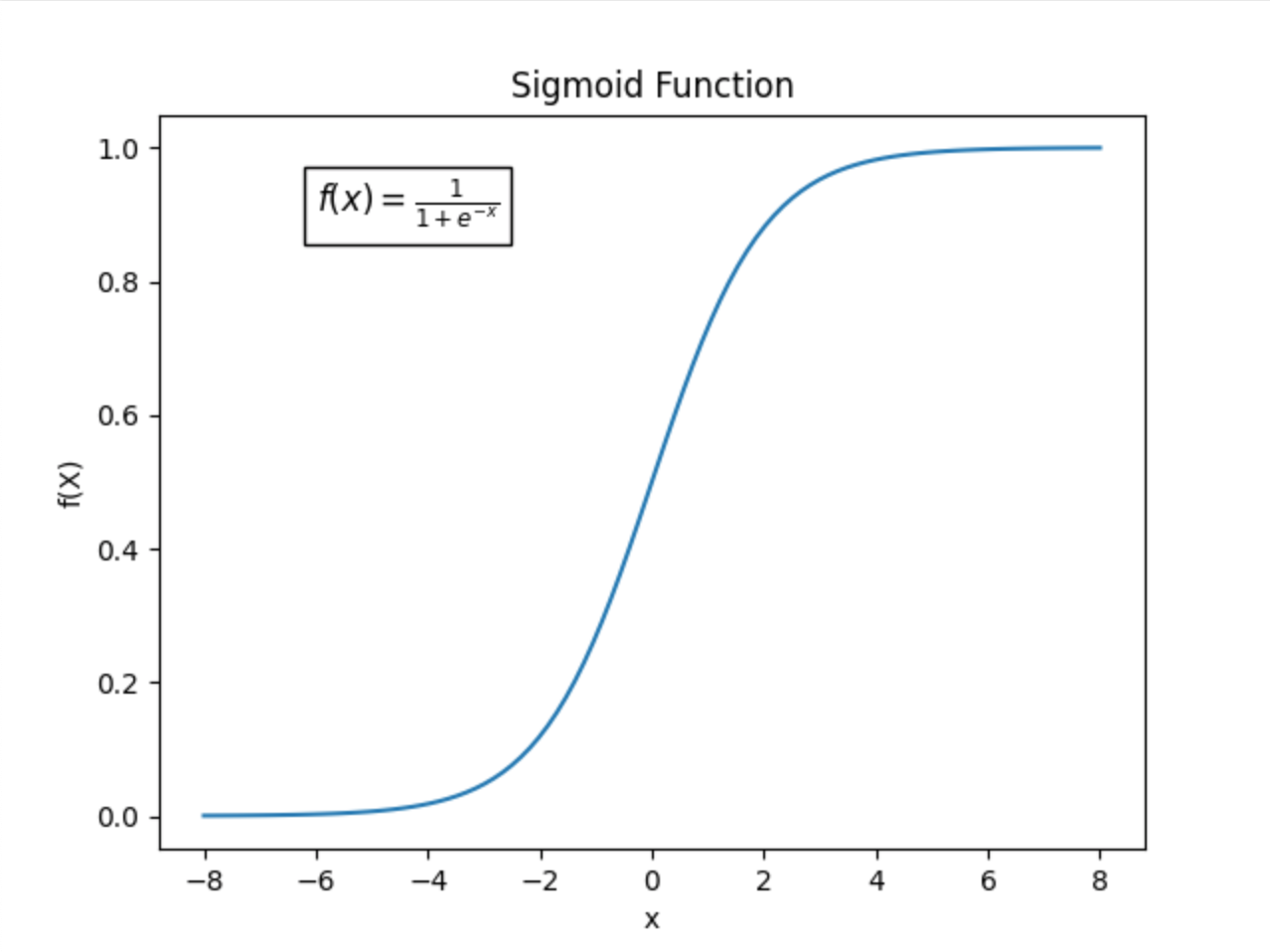
\(\sigma(z)=\frac{1}{1+e^{-z}}\), the sigmoid function, is used to map the result in the parenthesis to \([0,1]\) for \(\hat{y}\) is the probability.
Logistic Regression cost function
-
Denote \(z^{(i)}=w^{T}x^{(i)}+b\) and \(\hat{y}^{(i)}=\sigma(z^{(i)})\)
-
Goal: Given \(\{(x^{(1)},y^{(1)}),\dots,(x^{(m)},y^{(m)})\}\), want \(\hat{y}^{(i)}\approx y^{i}\).
-
Loss(error) function: A function to measure how good our prediction \(\hat{y}\) is on a single example. The small the loss function value, the better our prediction. Denoted by \(\mathcal L(\hat{y},y)\). Some common functions are shown below.
- \(\mathcal L(\hat{y},y)=\frac{1}{2}(\hat{y}-y)^{2}\)
- \(\mathcal L(\hat{y},y)=-(ylog\hat{y}+(1-y)log(1-\hat{y}))\)
-
Cost function: measures how well you are doing on the entire training set.
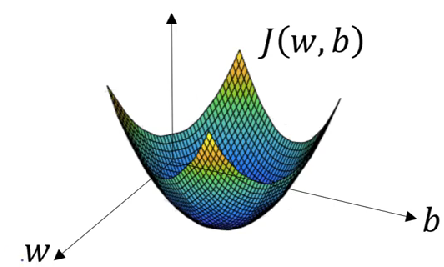
The function here is a convex function with global optimal.
Gradient Descent
-
Goal: Find \(w,b\) that minimize \(J(w,b)\).
-
Gradient Descent: initialize parameters with some values and repeatedly update them in the opposite gradient direction. Take \(w\) for example:
- \(\alpha\): Learning rate, controls how big a step we take on each iteration.
Derivatives with a Computation Graph
- Computation Graph: Assume wew want to compute \(J=3(a+bc)\)
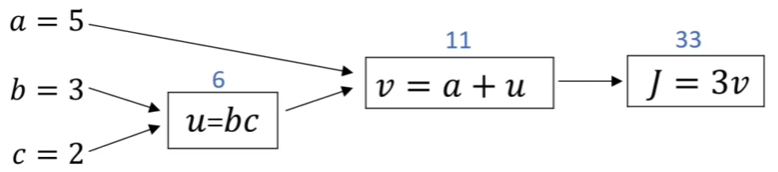
- \(\frac{dJ}{db}=\frac{dJ}{dv}\frac{dv}{du}\frac{du}{db}\)
- Logistic regression derivatives:
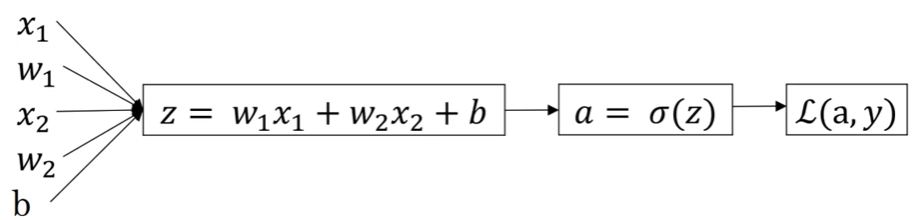
- In programming, we use
dxto represent \(\frac{dL}{dx}\).xcan be any variable here such asa,zand so on. da\(=\frac{dL}{da}=-\frac{y}{a}+\frac{1-y}{1-a}\)dz\(=\frac{dL}{da}\frac{da}{dz}=(-\frac{y}{a}+\frac{1-y}{1-a})a(1-a)=a-y\)dw1\(=\frac{dL}{dw_{1}}=\)dz\(\frac{dz}{dw_{1}}=x_{1}\)dzdb\(=\)dz
- In programming, we use
Logistic regression on m examples
We know that
So when computing derivatives on \(J\), we just need to take the average of derivatives on \(\mathcal L^{(i)}\).
i.e. dw1\(=\frac{1}{m}\sum_{i=1}^{m}\)dw1\(^{(i)}\), db\(=\frac{1}{m}\sum_{i=1}^{m}\)db\(^{(i)}\)
The algorithm is shown below:
Python and Vectorization
Vectorization
Vectorization can significantly speed up calculation compared to using explicit for loops.
If we use time() function in time library to check the time comsuming, we will find that the Vectorization is hundreds of times faster than for loop.
One criterian is that always using built-in functions in Python or Numpy instead of explicit for loop.
Now we can apply vectorization to logistic regression.
When it comes to compute the prediction, recap the defination of matrix \(X\).
Here we define matrix \(Z\) and \(A\). Note that \(z^{(i)}=w^{T}x^{(i)}+b\) and \(a^{(i)}=\sigma(z^{(i)})\)
If writen in Python:
Z = np.dot(w.T, X) + b
A = sigmoid(Z)
dZ = A - Y
dw = np.dot(X, dZ.T) / m
db = np.sum(dZ) / m
w = w - alpha * dw
b = b - alpha * db
Shallow Neural Networks
Neural Network Representation
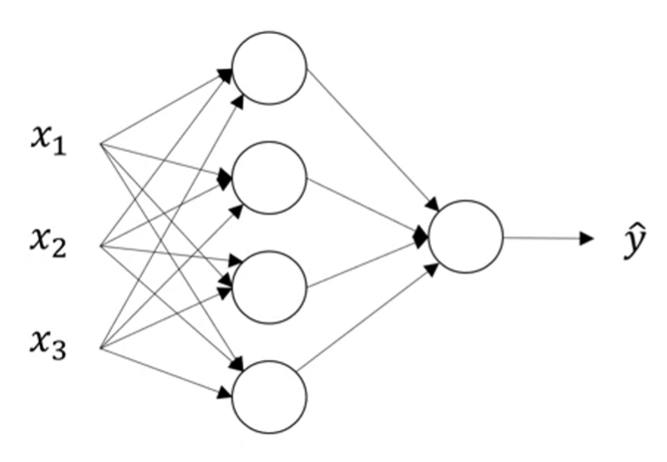 * Each column is call a layer. There are three layers here
* Input layer with \(x_{1},x_{2},x_{3}\)
* Hidden layer is the second column with 4 circles. The "hidden" means the value in this layer is invisible in the training set.
* Output layer, which output the final result.
* Layers are denoted by \(a^{[i]}\).
* Each column is call a layer. There are three layers here
* Input layer with \(x_{1},x_{2},x_{3}\)
* Hidden layer is the second column with 4 circles. The "hidden" means the value in this layer is invisible in the training set.
* Output layer, which output the final result.
* Layers are denoted by \(a^{[i]}\).
$$ a^{[0]}= \begin{bmatrix} x_{1} \ x_{2} \ x_{3} \ \end{bmatrix} \quad a^{[1]}= \begin{bmatrix} a_{1}^{[1]} \ a_{2}^{[1]} \ a_{3}^{[1]} \ a_{4}^{[1]} \ \end{bmatrix} \quad a^{[2]}=\hat{y} $$ * \(a\) means activate here. This example is a two layer NN since we don't count input layer.
Computation
In each node in hidden layer, we repeat the same computing way.
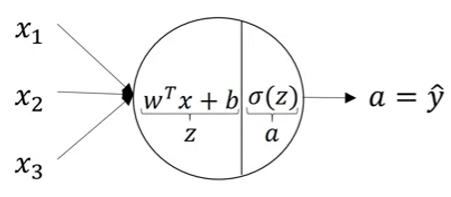
For the entire network,
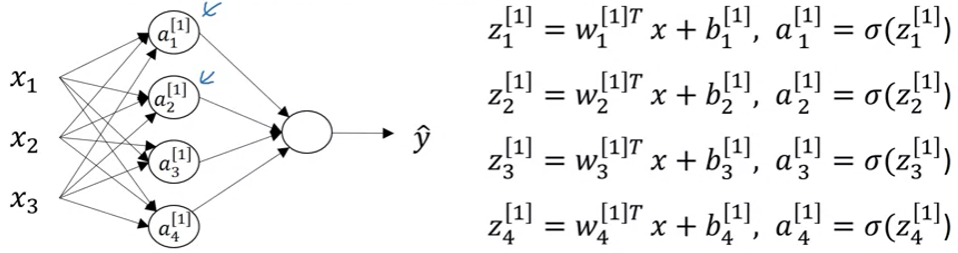
We can also vectorize it
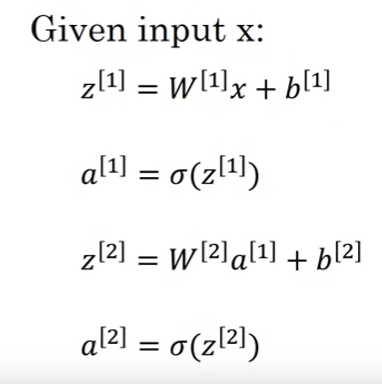
We can extend vectorization to multiple examples
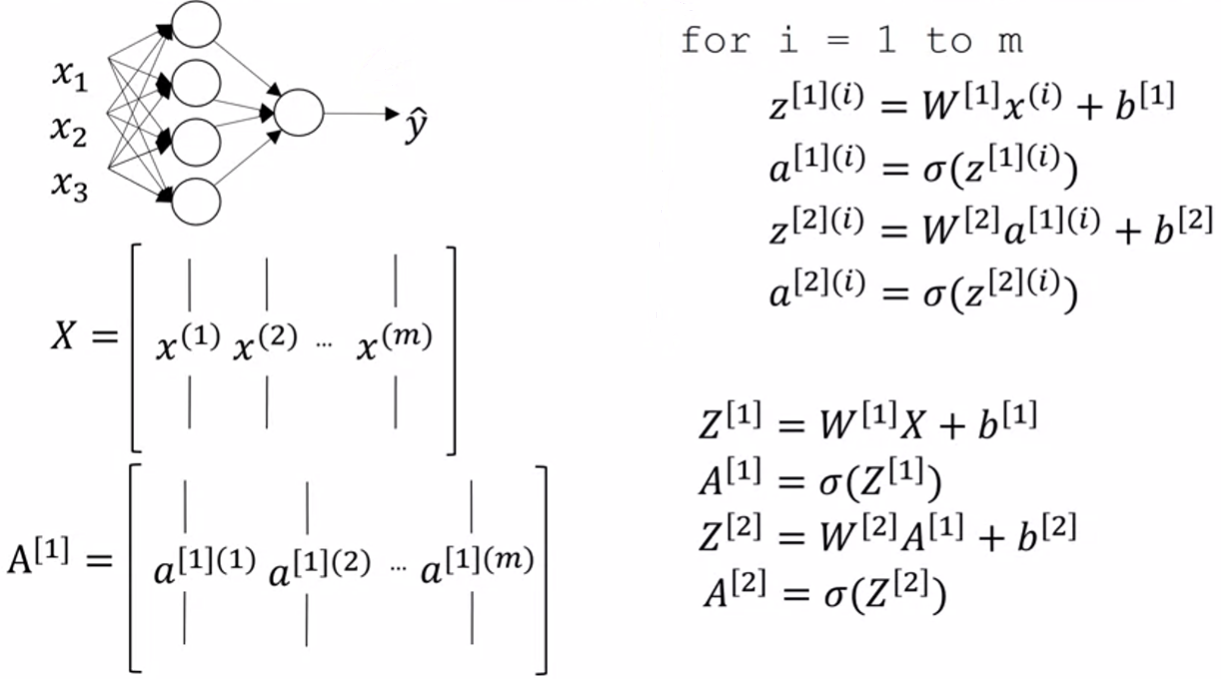
Note that actually \(X=A^{[0]}\)
Activation functions
There are different activation functions you can use in NN and different layers may have different activation functions. Now we can redefine that \(a^{[i]}=g^{[i]}(z^{[i]})\). \(g^{[i]}\) represents the activation function in the ith layer.
* sigmoid function: \(a=\sigma(z)\). Mostly used in the output layer in binary classification.
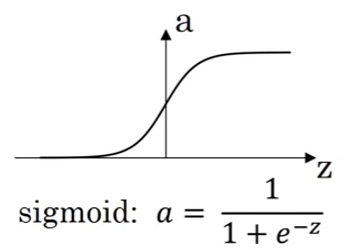
-
tanh function: \(a=\frac{e^{z}-e^{-z}}{e^{z}+e^{-z}}\). Always behaving better than sigmoid. A problem is when \(|z|\) is too large, the gradient of both sigmoid and tanh goes to 0
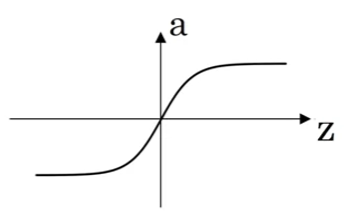
-
ReLU function: \(a=max(0, z)\). When z is negative, the gradient is 0. The gradient is 1 otherwise. Widely used.
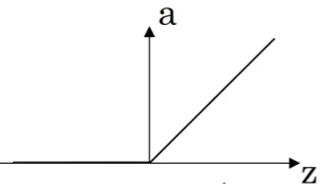
- Leaky ReLU: \(a=max(0.01z, z)\).
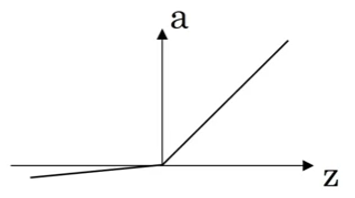
Why a Non-Linear Activation Function needed?
If we use Linear function as activation function or simply don't use activation function, the output \(y\) is just the linear combination of input \(X\). That means the result won't be better with more hidden layers.
Derivatives
- sigmoid: \(g'(z)=g(z)(1-g(z))\)
- tanh: \(g'(z)=1-g(z)^{2}\)
- ReLU: \(g'(z)=0, z<0 \ ; \ g'(z)=1,z\geq 0\)
Neural network gradients
Similar to logistic regression.

The left one is formula for single trainging example and the right one is for the entire training set. Note the \(*\) in the forth line means element-wise product.
Random initialization
Take the following NN for example:
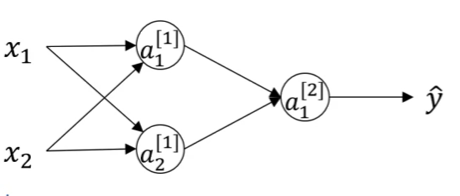
If we initialize \(W^{[1]}\) as all zero matrix, then \(a^{[1]}_{1}\) and \(a^{[1]}_{2}\) are same. The back propagation will also be the same, which turns out the hidden units in that layer are same.
We can initializate randomly.
W1 = np.random.rand((2, 2)) * 0.01
b1 = np.zero((2, 1))
W2 = np.random.rand((2, 2)) * 0.01
b2 = np.zero((2, 1))
\(b\) is ok to initialize to zero. We also times a \(0.01\) to make the initial value small for bigger gradient if we use sigmoid or tanh.
Deep neural network
Deep neural network has more hidden layers.
-
\(L\) denotes the number of layers.
-
\(n^{[l]}\) denotes the numbers of unit in layer \(l\).
Forward propagation
Here we store \(Z^{[l]}\) for computing backward propagation.
The dimension of \(W^{[l]}\) is \((n^{[l]},n^{[l-1]})\). The dimension of \(b^{[l]}\) is \((n^{[l]},1)\).
Although we always try to get rid of explicit for loop, a for loop is still necessary to traverse the \(L\) layers.
Backward propagation
In an iteration, we first use forward propagation to get \(\hat{y}\), compute \(\mathcal L(\hat{y},y)\) and then use back propagation to get those gradients.
Hyperparameters
- Parameters: \(W^{[1]},b^{[1]},W^{[2]},b^{[2]}\dots\)
- Hyperparameters: parameters that control the above ultimate parameters
- learning rate \(\alpha\)
- iteration times
- number of hidden layers \(L\)
- number of hidden units \(n^{[1]},n^{[2]}\dots\)
- choice of activation functions