4 Dimension Gaussian Splatting
Gaussian Distribution
Covariance
For a given random vector \(X:\Omega \rightarrow R^{n}\), its covariance matrix \(\Sigma\) is the \(n\times n\) square matrix whose extries are given by \(\Sigma_{ij}=Cov[X_{i},X_{j}]=E[(X_{i}-E[X_{i}])(X_{j}-E[X_{j}])]\)
Proposition: Suppose that \(\Sigma\) is the covariance matrix corresponding to some random vector \(X\). Then \(\Sigma\) is symmetric positive semidefinite
positive semidefinite
A symmetric matrix \(A\in S^{n}\) is positive semidefinite (PSD) if for all vectors \(x^{T}Ax\geq 0\)
\(\textit{proof}\text{: For any vector }z\in R^{n} \text{, observe that}\)
\(\text{Observe that the quantity inside the brackets is of the form}\)
\(\text{, which complete the proof}\)
Gaussian Distribution
- \(X\sim Normal(\mu,\sigma^{2})\): also known as univariate Gaussian distribution
- \(X\sim \mathcal{N}(\mu,\Sigma)\) For multivariate Gaussian, where mean \(\mu\in R^{d}\) and covariance matrix \(\Sigma\) is symmetric positive definite \(d\times d\) matrix
Proposition: \(\Sigma=E[(X-\mu)(X-\mu)^{T}]=E[X^{2}]-\mu\mu^{T}\)
Note
In the definition of multivariate Gaussians, we required that the covariance matrix \(\Sigma\) be symmetric positive definite. That's because we need \(\Sigma^{-1}\) exists, which means \(\Sigma\) is full rank. Since any full rank symmetric positive semidefinite matrix is necessarily symmetric positive definite, it follows that \(\Sigma\) must be symmetric positive definite.
Isocontour
Note
For a function \(f : R^2 → R\), an isocontour is a set of the form \(\{x\in R^{2}:f(x)=c\}\) for some \(c\in R\)
Consider the case where \(d=2\) and \(\Sigma\) is diagonal. For some constant \(c\in R\) and all \(x1,x2\in R\), we have
Defining
It follows that
When \(\Sigma\) is diagonal, it is the equation of an axis-aligned ellipse, while a rotated ellipses when not diagonal.
In \(d\) dimensional case, the level sets form geometrical structures known as ellipsoid in \(R^{d}\)
Closure properties
\(\textbf{Theorem:}\text{ Suppose that }y\sim\mathcal{N}(\mu,\Sigma)\text{ and }z\sim\mathcal{N}(\mu',\Sigma')\text{ are independent }\\ \text{Gaussian distributed random variables, where }\mu,\mu'\in R^{d}\text{ and }\Sigma,\Sigma'\in S^{d}_{++}\text{. Then, their sum is also Gaussian:}\)
\(\textbf{Theorem:}\text{ Suppose that }\)
\(\text{where }x_{A}\in R^{n},x_{B}\in R^{d}\text{ and the dimensions of the mean vectors and covariance matrix subblocks are chosen }\\ \text{to match }x_{A}\text{ and }x_{B}\text{. Then, the marginal densities are Gaussian:}\)
\(\textbf{Theorem:}\text{ Suppose that }\)
\(\text{where }x_{A}\in R^{n},x_{B}\in R^{d}\text{ and the dimensions of the mean vectors and covariance matrix subblocks are chosen }\\ \text{to match }x_{A}\text{ and }x_{B}\text{. Then, the conditional densities are Gaussian:}\)
Decomposition
Given that the covariance matrix is positive definite, it can be diagonalize in the following format:
\(\Lambda\) here is a diagonal matrix. We can consider it as a scaling matrix \(S\) and \(U\) as a rotation matrix \(R\).
When optimization \(\Sigma\), the gradient descent may not preserve the property of positive definite. We can equivalently optimize \(R\) and \(S\) separately, using a \(3D\) vecter \(s\) for scaling and a quaternion \(q\) to represent rotation. Making sure to normalize \(q\) to obtain a valid unit quaternion.
Volumn Rendering
backward mapping algorithm: shoot rays through pixels on the image plane into the volume data
forward mapping alogorithm: map the data onto the image plane
rendering pipeline
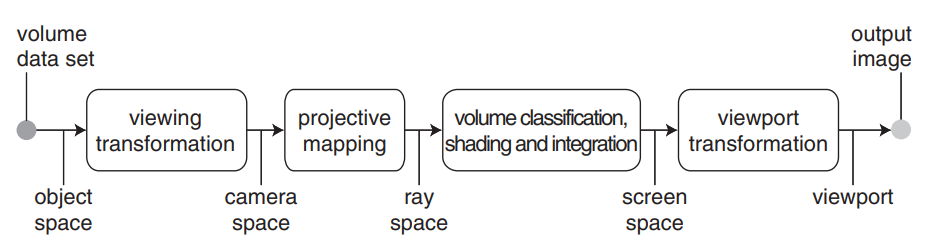
Splatting Alogorithm
We denote a point in ray space by a column vector of three coordinates \(\mathbf{x}=(x_0,x_1,x_2)^{T}\). The coordinates \(x_0\) and \(x_1\) specify a point on the projection plane and \(x_2\) specifes the Euclidean distance from the center of projection to a point on the viewing ray. Here we use the abbreviation \(\mathbf{\hat{x}}=(x_0,x_1)^{T}\).
The volume rendering equation describes the light intensity \(I_{\lambda}(\hat{\mathbf{x}})\) at wavelength \(\lambda\) that reaches the center of projection along the ray \(\hat{\mathbf{x}}\) with length \(L\):
-
\(g(\mathbf{x})\) is the extinction function that defines the rate of light occlusion, and \(c_{\lambda}(\mathbf{x})\) is an emission coefficient.
-
\(c_{\lambda}(\mathbf{x})g(\mathbf{x})\) describes the light intensity scattered in the direction of the ray \(\hat{\mathbf{x}}\) at the point \(x_2\).
-
The exponential term can be interpreted as an attenuation factor.
Now let's make several assumptions
-
The volume consists of individual particles that absorb and emit light. Given weight cofficient \(g_k\) and reconstruction kernels \(r_{k}(\mathbf{x})\), we have \(g(\mathbf{x})=\sum_{k}g_kr_{k}(\mathbf{x})\)
-
Local support areas do not overlap along a ray \(\hat{\mathbf{x}}\), and the reconstruction kernels are ordered front to back.
-
The emission coefficient is constant in the support of each reconstruction kernel along a ray, hence we use the notation \(c_{\lambda k}(\hat{\mathbf{x}})=c_{\lambda}(\hat{\mathbf{x}},\xi)\)
-
Approximate the exponential function with the first two terms of its Taylor expansion, thus \(e^{x}\approx 1-x\)
-
Ignore self-occlusion
Exploiting these assumptions, yielding:
where \(q_{j}(\hat{\mathbf{x}})\) denotes an integrated reconstruction kernel, hence:
The Viewing Transformation
Denote the Gaussian reconstruction kernels in object space by \(r_{k}''(\mathbf{t})=\mathcal{G}_{\mathbf{V''}}(\mathbf{t}-\mathbf{t_k})\), where \(\mathbf{t_k}\) are the voxel positions of center of kernel.
Denote camera coordinates by a vector \(\mathbf{u}=(u_0,u_1,u_2)^{T}\). Object coordinates are transformed to camera coordinates using an affine mapping \(\mathbf{u}=\varphi(\mathbf{t})=\mathbf{Wt+d}\), called viewing tranformation.
Now we can transform the reconstruction kernels \(\mathcal{G}_{\mathbf{V''}}(\mathbf{t}-\mathbf{t_k})\) to camera space:
where \(\mathbf{u_k}=\varphi(\mathbf{t_k})\) is the center of the Gaussian in camera coordinates and \(\mathbf{V'}_{k}=\mathbf{W}\mathbf{V''}_{k}\mathbf{W}^{T}\) is the variance matrix in camera coordinates.
The Projective Transformation
In camera space, The ray intersecting the center of projection and the point \((x_0, x_1)\) on the projection plane is called a viewing ray.
To facilitate analiytical integration of volumn function, we need to transform the camera space to ray space such that the viewing rays are parallel to a coordinate axis. The projective transformation converts camera coordinates to ray coordinates.
Camera space is defined such that the origin of the camera coordinate system is at the center of projection and the projection plane is the plane \(u_{2}=1\). Camera space and ray space are related by the mapping \(\mathbf{x=m(u)}\).
where \(l=\Vert(x_{0},x_{1},1)^{T}\Vert\).
Unfortunately, these mappings are not affine. The Gaussian after the transformation may not still Gaussian. To solve this problem, we introduce the local affine approximation \(m_{uk}\) of the projective transformation. It is defined by the first two terms of the Taylor expansion of \(\mathbf{m}\) at the point \(\mathbf{u}_k\):
where \(\mathbf{x}_k=\mathbf{m(u_k)}\) is the center of a Gaussian in ray space and the Jacobian \(\mathbf{J_{u_k}}\) is given by the partial derivatives of \(\mathbf{m}\) at the point \(\mathbf{u}_k\).
This yields the local affine approximation of reconstruction kernels to ray space:
where \(\mathbf{V}_k\) is the variance matrix in ray coordinates:
Spherical Harmonic Functions
Spherical harmonics form an orthogonal basis for functions defined over the sphere, with low degree harmonics encoding smooth (more Lambertian) changes in color and higher degree harmonics encoding higher-frequency (more specular) effects.
-
\(l\): the degree (non-negative integer)
-
\(m\): the order (integer such that \(−l\leq m\leq l\))
-
\(c_{l}^{m}\): SH coefficients
- \(Y_{l}^{m}\): SH functions, where \(P_{l}^{m}\) are the associated Legendre polynomials, \(\theta\) is the colatitude(0 to \(\pi\)), and \(\phi\) is the longitude(0 to \(2\pi\))
Structural Similarity Index Measure
The structural similarity index measure (SSIM) is a method for predicting the perceived quality of digital television and cinematic pictures, as well as other kinds of digital images and videos. It is also used for measuring the similarity between two images.
Algorithm
The SSIM index is calculated on various windows of an image. The SSIM formula is based on three comparison measurements between two window \(x\) and \(y\) of common size \(N\times N\) is: luminance (\(l\)), contrast (\(c\)) and structure (\(s\)). The individual comparison functions are:
where:
-
\(\mu_{x}\) the pixel sample mean of \(x\)
-
\(\mu_{y}\) the pixel sample mean of \(y\)
-
\(\sigma_{x}^{2}\) the variance of \(x\)
-
\(\sigma_{y}^{2}\) the variance of \(x\)
-
\(\sigma_{xy}\) the covariance of \(x\) and \(y\)
-
\(c_{1}=(k_1L)^{2},c_{2}=(k_2L)^2=2c_3\) two variables to stabilize the division with weak denominator
-
\(L\) the dynamic range of the pixel-values (typically is \(2^{\#bits per pixel}-1\))
-
\(k_1=0.01\) and \(k_2=0.03\) by default.
SSIM is then a weighted combination of those comparative measures:
Setting the weights \(\alpha,\beta,\gamma\) to 1, the formula can be reduced to the form below:
Structural Dissimilarity
Structural dissimilarity (DSSIM) may be derived from SSIM, though it does not constitute a distance function as the triangle inequality is not necessarily satisfied.